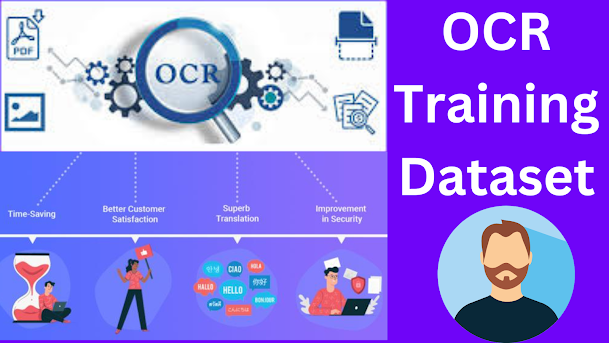
OCR Training Dataset For Deep Learning Models Introduction Before the 2012 revolution in deep learning, various OCR implementations were available. OCR is still a complex issue, even though it was generally believed to have been solved. It is mainly the case when text images are taken in an uncontrolled environment. I'm referring to the images' complex backgrounds, including lightning, noise, various fonts, and geometrical aberrations. However, numerous datasets are available in English, and finding data for different languages can take time and effort. Different datasets present different issues that need to be resolved. Here are some examples of the kinds of data that are commonly used to address machine learning OCR problems. This Information Age is all about AI. It's great for people who use it and also helps businesses grow, and it's generally one the clear evidence of the progress of the human race, where machines perform many mundane or tedious tasks. Technology ...

.png)
.png)



.webp)